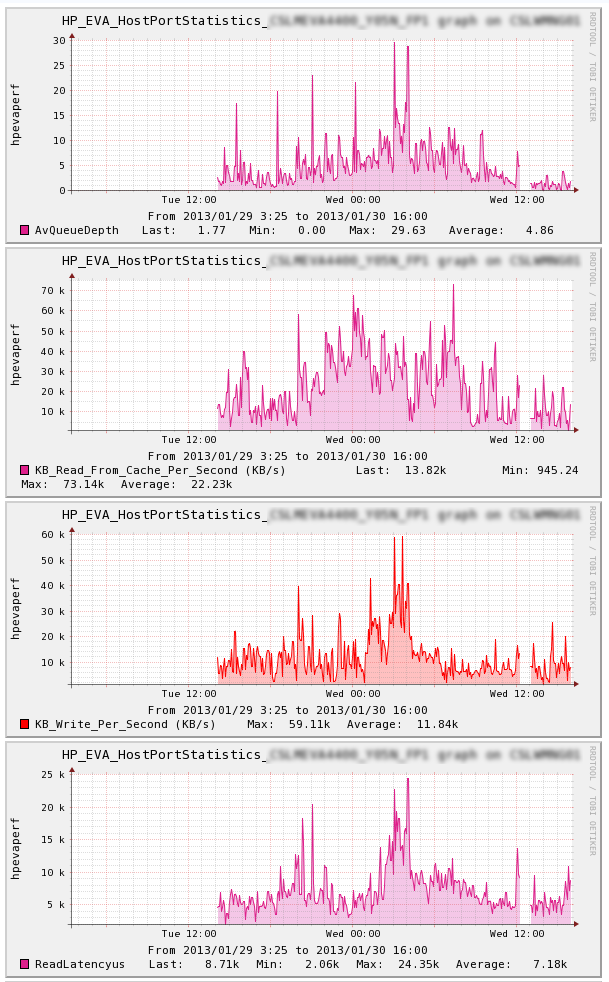
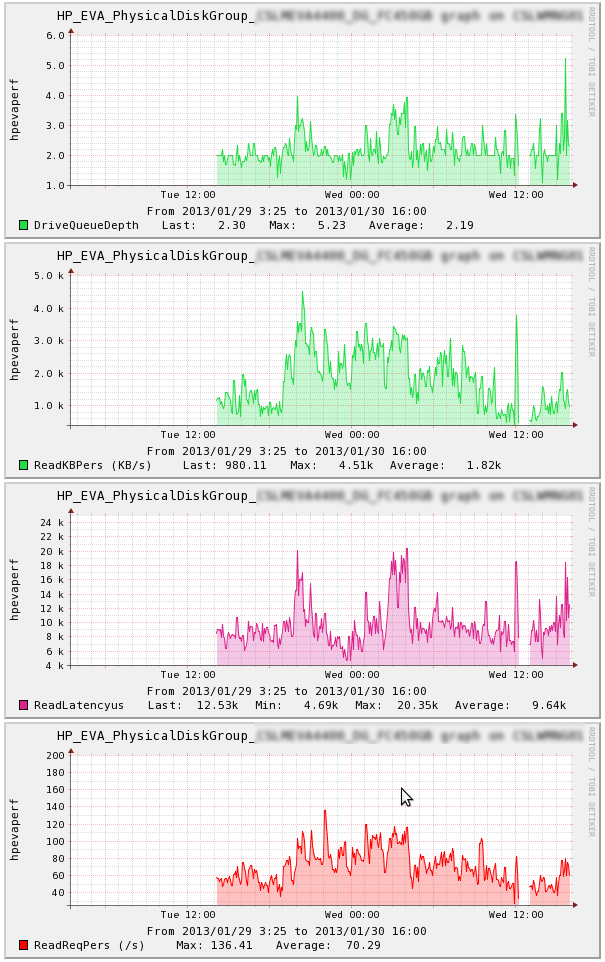
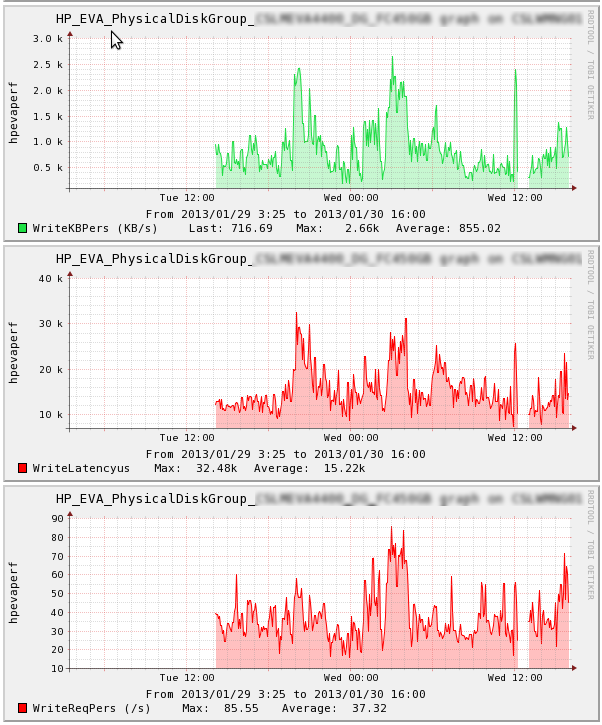
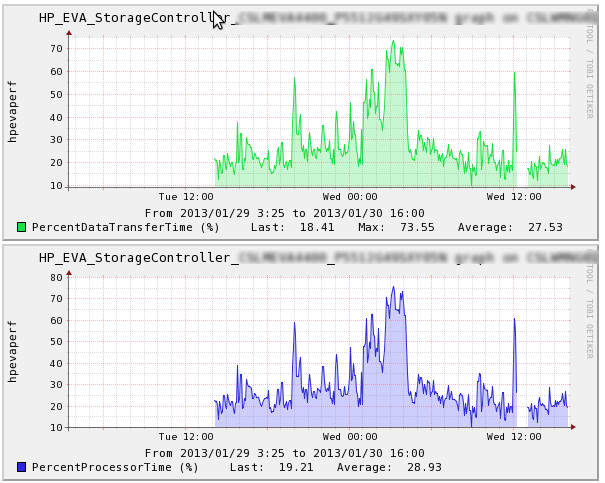
Hi Folks,
I describe in this part my custom installation of PNP4Nagios for distributed monitoring. Here my plateform, I suppose you can install nagios, thruk, and livestatus broker (unix/tcp socket mode). I have 3 servers :
- server1 : nagios, thruk, livestatus
- server2 : nagios, livestatus
- server3 : nagios, livestatus
How it work ?
- PNP4nagios will be installed on server1
- NCPD will be running on on server1
- NFS server will be installed on server1
- Npcdmod broker (npcdmod.o) will be used by server1, server2, server3
- My server1, server2, server3 are Centos 6
Why ? Because Thruk provides a interesting feature, you can build report SLA and integrate PNP graph. Thruk can retrieve graphs of several PNP4Nagios. But you must to define different “action_url” on the host/service definition. Not very easy when you use template. That is why I am going to install a single PNP.
Server1 :
Install pnp4nagios and NFS daemon :
# yum install pnp4nagios nfs |
Enabled npcd daemon a boot and restart Apache
1 2 | # chkconfig npcd on # /etc/init.d/httpd reload |
Install NFS packages
1 | # yum install nfs-utils nfs-utils-lib |
Configuration NFS /etc/exports
1 2 | /var/spool/pnp4nagios/ server2(rw,sync) /var/spool/pnp4nagios/ server3(rw,sync) |
Restart NFS daemon
1 | # /etc/init.d/nfs restart |
To preserve permission on /var/spool/pnp4nagios, nagios user must have the same id on server1, server2, server3.
server1 # id nagios uid=100(nagios) gid=101(nagios) groups=101(nagios) server2 # id nagios uid=100(nagios) gid=101(nagios) groups=101(nagios) server3 # id nagios uid=100(nagios) gid=101(nagios) groups=101(nagios) |
Configuration NPCD file : /etc/pnp4nagios/npcd.cfg
1 2 | perfdata_spool_filename = perfdata-server1 log_level = 1 |
Restart NPCD daemon
1 | # /etc/init.d/npcd restart |
Configuration Thruk with PNP4nagios. Create .thruk file in Apache home directory (/var/www/.thruk)
1 2 3 | touch /var/www/.thruk chown apache:apache /var/www/.thruk vi /var/www/.thruk |
Paste the content :
1 2 | export PNP_ETC="/etc/pnp4nagios" export PNP_INDEX="/usr/share/nagios/html/pnp4nagios/index.php" |
Restart thruk
1 | # /etc/init.d/thruk restart |
Add broker npcdmod in /etc/nagios/nagios.cfg file
1 | broker_module=/usr/lib/nagios/npcdmod.o config_file=/etc/pnp4nagios/npcd.cfg |
Restart Nagios
1 | # /etc/init.d/nagios restart |
Server2
To use npcdmod.o module, we need install pnp4nagios
1 | # yum install pnp4nagios |
Modify the /etc/pnp4nagios/npcd.cfg file in order to identify perfdata on server2
1 | perfdata_spool_filename = perfdata-server2 |
Edit /etc/fstab file to mount NFS share
server1:/var/spool/pnp4nagios /var/spool/pnp4nagios nfs defaults 0 0 |
Mount /var/spool/pnp4nagios
1 | # mount /var/spool/pnp4nagios |
Edit file /etc/nagios/nagios.cfg and add the npcdmod broker
1 | broker_module=/usr/lib/nagios/npcdmod.o config_file=/etc/pnp4nagios/npcd.cfg |
1 | # /etc/init.d/nagios restart |
Server3
To use npcdmod.o module, we need install pnp4nagios
1 | # yum install pnp4nagios |
Modify the /etc/pnp4nagios/npcd.cfg file in order to identify perfdata on server3
1 | perfdata_spool_filename = perfdata-server3 |
Edit /etc/fstab file to mount NFS share
server1:/var/spool/pnp4nagios /var/spool/pnp4nagios nfs defaults 0 0 |
Mount /var/spool/pnp4nagios
1 | # mount /var/spool/pnp4nagios |
Edit file /etc/nagios/nagios.cfg and add the npcdmod broker
1 | broker_module=/usr/lib/nagios/npcdmod.o config_file=/etc/pnp4nagios/npcd.cfg |
1 | # /etc/init.d/nagios restart |
How NCP daemon works ?
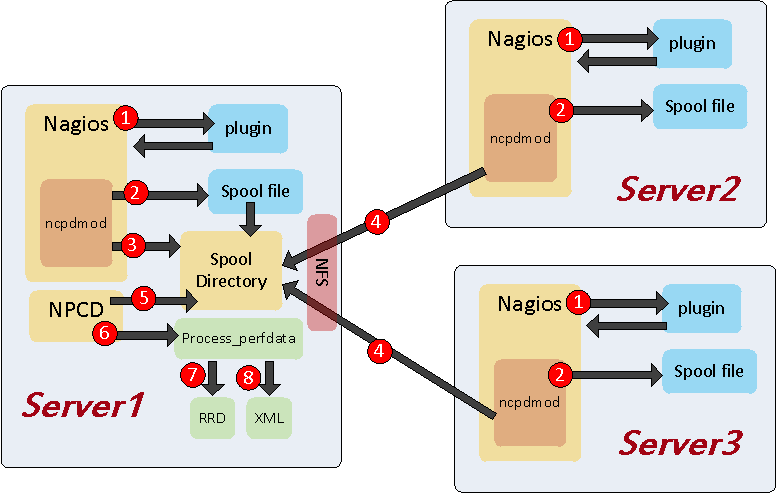
- Nagios execute plugin
- Npcdmod Store perfdata into Spool files
- On server1 npcdmod move Spool file to Spool Directory
- On server2 or server3 npcdmod move Spool file to NFS Share “Spool Directory”
- NPCD scan Spool directory
- Execute perfdata command
- Update RRD Database
- Write XML Meta data
Server1
Thruk local config : /etc/thruk/thruk_local.conf
<Component Thruk::Backend>
<peer>
name = server1
type = livestatus
<options>
peer = /var/log/nagios/rw/live
resource_file = /etc/nagios/resource.cfg
</options>
</peer>
<peer>
name = server2
type = livestatus
<options>
peer = server2:6557
</options>
</peer>
<peer>
name = server3
type = livestatus
<options>
peer = server3:6557
</options>
</peer>
</Component>
Thruk interface : http://server1/thruk/
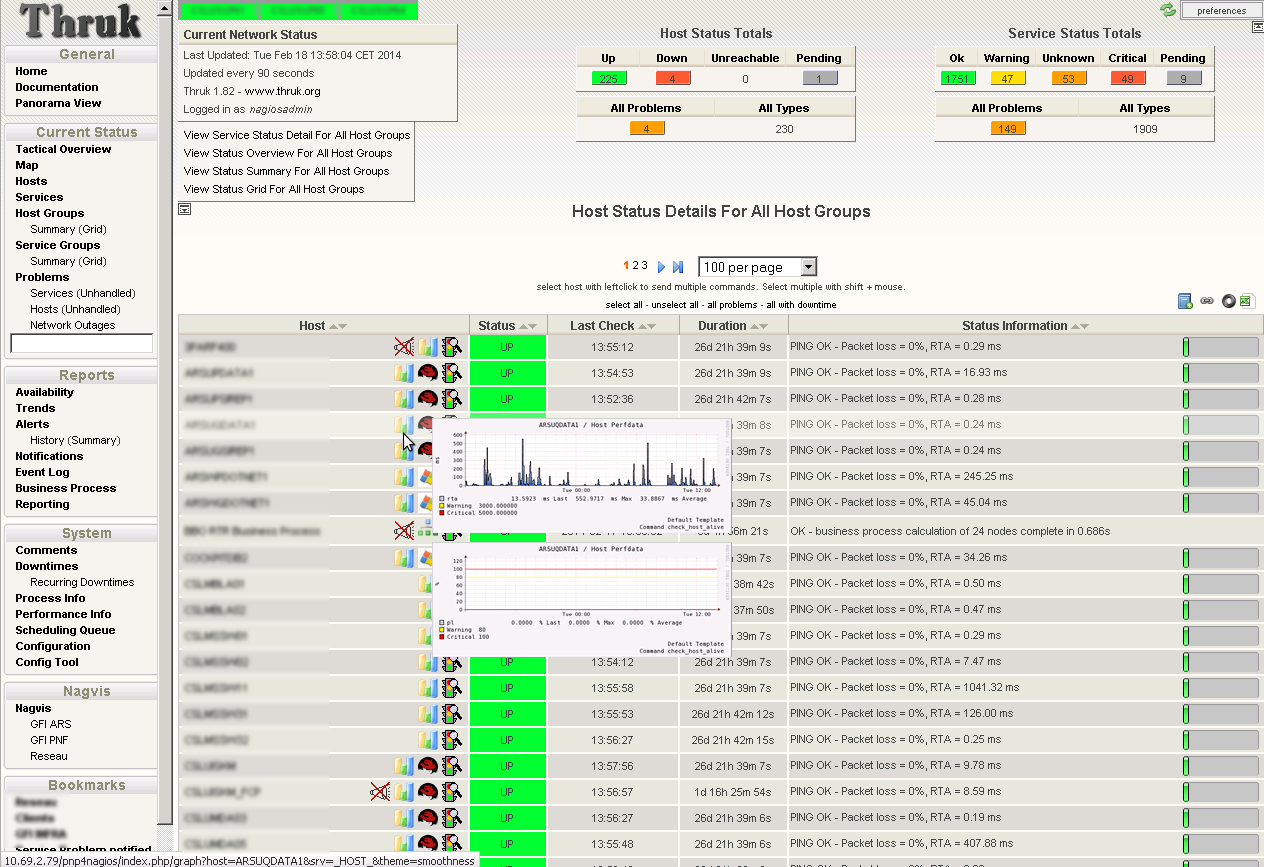
If you have no graph into pnp4nagios interface, change the log_level in /etc/pnp4nagios/npcd.cfg
log_level=-1
Restart the daemon
/etc/init.d/npcd restart
You see log in /var/log/pnp4nagios/npcd.log file
[02-18-2014 14:03:42] NPCD: No more files to process... waiting for 15 seconds [02-18-2014 14:03:57] NPCD: Processing file 'perfdata-server2.1392728630' [02-18-2014 14:03:57] NPCD: Processing file 'perfdata-server3.1392728625' [02-18-2014 14:03:57] NPCD: No more files to process... waiting for 15 seconds [02-18-2014 14:04:12] NPCD: Processing file 'perfdata-server2.1392728645' [02-18-2014 14:04:12] NPCD: Processing file 'perfdata-server3.1392728640' [02-18-2014 14:04:12] NPCD: No more files to process... waiting for 15 seconds [02-18-2014 14:04:27] NPCD: Processing file 'perfdata-server2.1392728660' [02-18-2014 14:04:27] NPCD: Processing file 'perfdata-server3.1392728655' [02-18-2014 14:04:27] NPCD: No more files to process... waiting for 15 second